 (018)
(018)Kathryn La Barre and Chris Dent (02)
klabarre@indiana.edu cjdent@indiana.edu (03)
Indiana University
011
Main Library
1320 E. 10th St. Bloomington
IN, USA
47405-3907
phone:
812-336-9136
http://ella.slis.indiana.edu/~klabarre/unrev_firstpage.html (04)
Abstract: Discusses ongoing work with the email archive of the Unrev-II list. Computational methods for determining aboutness of subjects, messages and threads will be tested using the archive contents. Extracted levels of aboutness could then be used in an iterative process to generate facets and to provide conceptual access to the archive. Hypothesis: Tools such as latent semantic analysis, vector space models, traditional concordancing, and self-organizing maps may be worthwhile tools to generate meaningful clusters in the dataset. These clusters would then be used as aids in the human process of facet analysis in order to generate a faceted access structure1 for the conceptual content of the archive or similar textual repositories. (05)
In late Fall of last year, participants on the Unrev-II listserv renewed a conversation in which the community began to wonder how best to create access to the conceptual content of the archived postings. The listserv was created in order to provide a discussion space for participants in the Unfinished Revolution Colloquium at Stanford (January until March 2000). Persons unable to participate in the colloquium and anyone interested in the activities of the Bootstrap Institute were invited to join the discussion. Recently the focus of the discussion group shifted to concrete actualization of Englebart's vision, and another discussion group superseded Unrev-II. The initial impetus for this inquiry is the fact that the Bootstrap Institute hopes to mine material from the Unrev-II list in order to create a Bootstrapping "handbook" for the creation of a Dynamic Knowledge Repository (DKR)2 and Open Hyperdocument System (OHS)3. The Bootstrap Institute4 envisions such a handbook as a tool useful "for more efficiently solving urgent, complex problems in the private and public sectors of world society". (07)
The threaded contents of Unrev-II are accessible at http://www.bootstrap.org/dkr/discussion/. The group has periodically expressed interest in enhanced access to such elements as archived references to books, websites and related projects. The list contains various other kinds of discussions: social concerns, tool developments and announcements of progress being made by the Bootstrap Institute. These materials mark the Unrev-II archive as a valuable knowledge repository. In a similar fashion, both the PORT-l list and the Peirce manuscripts affiliated with PORT (Peirce Online Repository Testbed) function in much the same way. Each of these entities serves as a knowledge repository; we posit that same level of conceptual access requested by the Unrev-II community will prove useful to PORT. The archive of Unrev-II postings represents a fertile area for testing tools that may prove useful in providing conceptual access to such knowledge repositories. (08)
As the members of the Unrev-II list prepared to close this archive, one of the members of the group, Henry van Eyken suggested that in order to come up with a way to have conceptual access to the list, a group of volunteers agree to assign keywords (in effect) to the postings, and to sort them by importance. Members of the list engaged in a discussion of faceted structures just prior to the closing of the list. Not much came of this effort. It is the intention of this project to use facet analysis in order to create a conceptual access tool for the archive. Rather than beginning with a set of pre-defined facets (or categories) and imposing these as keywords upon the holdings of the archive, we intend to use various methods of semantic processing (such as concordancing, vector-space analysis and latent semantic analysis) to create clusters of terms and concepts that will then be used to create a faceted access tool.5 (010)
The heart of our approach is to use the most effective semantic analysis tools to assist in the generation of conceptual clusters, which are then subject to further analysis by human evaluators. Clusters created by one method of semantic analysis will potentially have both degrees of similarity and divergence from one another. By enabling side-by-side comparison of various methods of semantic analysis, the means by which each method clusters and the potential utility of each method will emerge. (011)
We built a testbed for evaluating tools that can assist in cluster analysis. The testbed involves several aspects: the archive of the mailing list itself, semantic processing which will then result in retrieval and display of clusters of conceptually related concepts and a method of evaluating clusters in the web interface we have created to provide access to the archive. By the creation of this testbed, human evaluation of these differences will enable an examination of whether or not the differences between messages are of greater utility in the creation of an access structure, than measures of sameness. (012)
In order to create access to the text archive and to enable refinement of the access structure, a web tool has been created in order to allow selection of a particular cluster for evaluation. Current list members will be invited to view the access structure and to participate in refining the structure. Group members will also be able to code messages for meaning in various ways, ranking messages by order of importance, assigning keywords or generating a short phrase or two to indicate aboutness. From this level of coding, it will be possible to generate another level of semantic analysis. This is an iterative process, and we hope that the lessons learned can extend to building access to other textual repositories, such as those supported by PORT, in much the same manner (and in a much less time-intensive fashion). (014)
Thus far, experimentation has been divided among creating a database representation of the archive, latent semantic analysis of a small subset of the data and extraction of recommended resources submitted by the members of the list. The data, consisting of ~27MB mbox format mail archive, was parsed and injected into an Oracle 8 database by a Perl script, parser.pl (http://ella.slis.indiana.edu/~cjdent/parser.pl). The text file contains 3679 messages and spans a time period of two years, January 2000 until January 2002. Mail messages that did not have a MIME Content-Type of text/plain were not installed in the database. This lowered the total number of messages from 3685 to 3131. There are a total of 1550 different subjects and 154 individuals have posted messages to the list. (015)
An interface to the database will be used to present clusters discovered by the various methods of computational analysis and further processed by human evaluators. This interface is designed to allow multi-dimensional traversal of the archive: through clusters; between clusters; as well as by author, subject and date. We contemplate that this traversal function will allow comparisons that will assist human evaluators attribute facets to the messages. This function will also confirm facets suggested by the computational methods, as the group further refines the access structure by both searching, and by coding the messages in the archive. A prototype of the interface is available on the Internet (http://ella.slis.indiana.edu/~cjdent/unrev/index.cgi). (016)
The latent semantic analysis of a small subset of the archive resulted in clusters of similar messages by threads. Here are two examples of the clusters resulting from analysis of the small dataset and the processes used to create them. Clusters are the result of similarity matrices visualized using a spring embedding algorithm in a simple Java application. (Further discussion of these clusters, and other visualizations are available at (http://ella.slis.indiana.edu/~cjdent/project3/figures.html). (017)
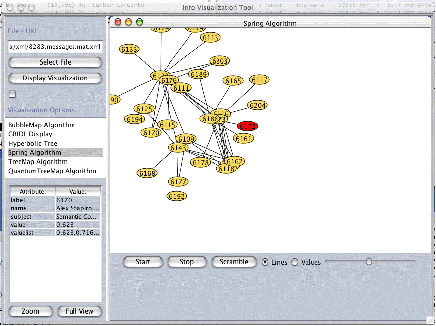
Figure 1 Similarity between Threads (019)
Figure 1 demonstrates the similarity between the 11 largest threads in the database. Node numbers represent a unique identifier for the subject. On a Java mouseOver event the subject of the thread is revealed. Message 7038 appears to be a hub for the rest of the messages. This makes sense as the message started the mailing list and introduces the colloquium with which it is associated. 7442 introduces a discussion of why email is a better forum than web or news for what they will be discussing. 7239 and 7863 are related to that topic — in those threads the participants are discussing the technical requirements of an Open Hyperdocument System (OHS) and Dynamic Knowledge Requirement (DKR). It appears that the division between the hub centered on 7442 and the hub centered on 7038 is related to a difference between why the participants are doing what they are doing and how they are going to do it. This small exercise highlighted the critical importance of such tools for the success of this experiment. (020)
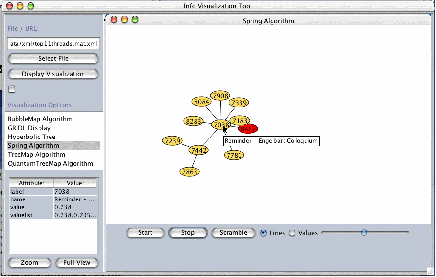
Figure 2 "Semantic Community Web Portal" (022)
Figure 2 contains 31 messages. This visualization demonstrates a complex, wide-ranging, but interrelated thread discussing the tools necessary for the construction of a web portal for the knowledge acquisition community. Hubs appear to focus between graphical visualization tools and other, text-based, tools. (023)
By the use of concordancing it has been possible to extract extract a bibliography of sources that are mentioned in the emails as well as an index of subject lines. (These items are available here: http://ella.slis.indiana.edu./~klabarre/unrev_books.html, http://ella.slis.indiana.edu/~klabarre/unrev_index.html). (024)
PORT is currently evaluating tools that attempt to distinguish means by which "inference processes in knowledge representation require human reasoning and which are better served by automated reasoning, as knowledge processing technology evolves, to accomplish effective partnerships between human and machine intelligence in any particular context of operation." (http://www.lml.acad.bg/iccs2002/PORT.htm) Our inquiry proceeds from the same framework. To what extent can the Unrev-II postings be subject to automated processing which will yield conceptual clusters, which can then be utilized in the creation of an access structure? We intend this inquiry to result in tool analysis, as well as increased conceptual access to the archive. Since this is an iterative process, increased access to the archive will both help and hinder our ability to evaluate the archive itself, and will concurrently shape the assumptions and methods we bring to the experiment. (026)
There are a number ways to approach creating access to an archive such as Unrev-II. One means relies on fully automated term and cluster generation. Another method relies on a combination of automated cluster generation with human intervention to label messages with facets. Yet another relies on human work most akin to traditional indexing or tagging of messages without computational assistance. Such tagging would occur either by the author at the time the message is generated, or by someone charged with maintenance of the archive. (028)
Having the ability both to automatically generate clusters and to tag messages would serve to enhance conceptual access in a way that neither method can do alone. Furthermore, it is possible to identify or classify new messages being added to the archive by representing the incoming messages as a vector and comparing that vector against the set of vectors that are the prototypical psuedo-documents representing existing clusters. However, testing with the Unrev-II archive revealed a valuable early lesson: the vector space model is easy to corrupt. Irrelevant text added by mailing list software, divergent message lengths within the archive and the essentially chaotic nature of text in email can distort calculations of similarity. Stop word lists are also a challenge in this multi-faceted list as the type to token ratio is quite high. Post hoc analysis of the clusters by human evaluators can catch and make adjustments for errors in the automated processes. (029)
The current state of this inquiry is quite preliminary. We face a number of challenges, primary among them, the format of the data. For various reasons, email is considered "dirty data" as it contains headers inserted by the mail sending protocol and in this case, footers that were inserted by the mailing software. There are few standard conventions for replying to an email message, just as there is no guarantee that messages will actually thread according to content or response, since often the content of a message differs from the subject line and email clients do not conform to reference standards. Another significant challenge is the sheer volume of the text in an archive of even a moderately active list. Searching most email archives is limited to searching by three components: date, subject and author. These limitations make finding specific conceptual content difficult unless the searcher already knows one of these specific items. (030)
Additions to the web interface functionality will be several. List members will be given the opportunity to code for the relative importance of any given message. The purpose will be to allow coding by consensus in order to determine those messages that need immediate attention. Originally, talk on the list revolved around culling out the "dandruff" and only keeping the meat of the archive. We decided instead to keep all messages in the database, and to allow participants to code for the relative importance of each message according to community practice and goals. Other coding possibilities will be offered in addition to coding by importance. Assignment of keywords will be possible as well. (031)
By allowing the community to code messages, it will be possible to compare human generated access terms with computer generated terms. Participants will also be invited to append short conceptual statements of aboutness to messages. Both the assigned terms and phrases can be subject to further semantic analysis in order to determine facets or to refine those that are being used at any given point. The process of term and facet refinement can be fully automated in support of this iterative process. (032)
Although much work remains, our initial investigations have shown much promise. The combination of computational tools to automate cluster identification with computer-based tools to assist human-based evaluation and refinement of those clusters may prove useful in generating conceptual access to the Unrev-II archive based on flexible faceted structures. Our investigations will reveal which tools and which tasks are most suited to machine intelligence, which are most suited to human intelligence and the best means by which to facilitate effective partnerships between the two. (034)
Atherton, P. (1965). Ranganathan's Classification Ideas: An Analytico-Synthetic Discussion. Library Resources and Technical Services 9(4) p. 463-472. (036)
Berry, M. et al. (1993). SVDPACKC (Version 1.0). Available at http://www.netlib.org/svdpack/index.html (037)
Bootstrap Institute. (2002). Retrieved March 7, 2002 from http://www.bootstrap.org/ (038)
Unrev-II mailing list archive. (2002). Retrieved May 3, 2002 from http://www.bootstrap.org/dkr/discussion/subject.html (039)
Vickery, B. C. (1960). Faceted classification. London: ASLIB (040)
Xao, M. & BÖrner, K. (2001). Information Visualization Software Repository. Retrieved March 14, 2002 from http://ella.slis.indiana.edu/~katy/L697/code/ (041)
1 For further discussions of faceting refer to Atherton (1965), and Vickery (1960). (043)
2 http://www.eekim.com/talks/cap2002/index-3.html (044)
3 http://www.bootstrap.org/ohs/index.jsp (045)
4 http://www.bootstrap.org (046)
5 Uta Priss conducted one such experiment in faceted access but used a dataset that was already in a database. View one of the FaIR displays here: http://ella.slis.indiana.edu/~upriss/cgi/fair (047)